[Hive] Hive 란?
개요
Hive에 대한 개념 정리와 간단한 실습을 진행해보며 Hive의 구동원리 아키텍쳐에 대해 알아가 보도록 하겠습니다.
Hive 란?
Hive는 Hadoop에서 돌아가는 Data Warehousing Solution 입니다. MapReudce는 Java 기반이기 때문에 Java에 대한 역량이 부족한 데이터 엔지니어에게는 진입 장벽이 높습니다. 따라서 Hive를 통해 SQL문을 MapReduce로 변환 시켜주면서 진입 장벽을 낮추었습니다.
진행 과정은 Hive에서 SQL문을 MapReduce로 변환 시켜주고, 이를 Hadoop이 처리하는 순서로 진행됩니다.
즉, Hive는 단순히 SQL을 MapReduce로 변환 시켜주는 작업을 진행하고, Hadoop이 일을 처리하는 역할을 수행합니다. 따라서 엄밀히 이야기 한다면 Hive는 Databaes가 아니지만 통용해서 이야기 할때에는 Database라고 지칭합니다.
Hive는 Hadoop 과의 통신과 Compile 해주는 역할을 수행합니다.
RDB의 데이터베이스, 테이블과 같은 형태로 HDFS에 저장된 데이터의 구조를 정의하는 방법을 제공하며, 이 데이터를 대상으로 HiveQL 쿼리를 이용해 데이터를 조회하는 방법을 제공합니다.
Hive Table Limitations
1) Write Only
대용량의 파일 중에 update, delete 과정에서 성능적인 Issue가 발생하기 때문에 Write Only만 지원합니다.
ex) 1억건의 Data 중에 하나의 Data를 갱신한다 생각하면 그 Data를 찾기 위해 약 1억건을 스캔해야 합니다. 이로 인해 성능적인 Issue가 발생하게 됩니다.
2) HDFS의 한계를 그대로 물려 받습니다.
3) Hadoop은 대용량을 위한 프레임 워크입니다.
4) 변화라는 것에 Limited가 걸려있습니다.
5) Insert, Update, Delete에 대해 가능하지만, Hive 3.x 에서는 Limited 걸려 있습니다.
6) Hive Issue 문제는 대부분 Hadoop Issue라고 생각하면 됩니다.
Hive 구성요소
1) UI
- 사용자가 쿼리 및 기타 작업을 시스템에 제출하는 사용자 인터페이스입니다.
2) Driver
- 사용자가 쿼리를 입력하면, 그 쿼리를 입력받고 작업을 진행합니다.
- 사용자 세션을 구현하고, JDBC/ODBC 인터페이스 API를 제공합니다.
3) Compiler
- MetaStore를 참고하여 쿼리 구문을 분석하고 실행계획을 생성합니다.
4) Metastore
- DB, Table, Partition의 정보를 저장하는 역할을 수행합니다.
5) Excution Engine
- Compiler에 의해 생성된 실행 계획을 실행합니다.
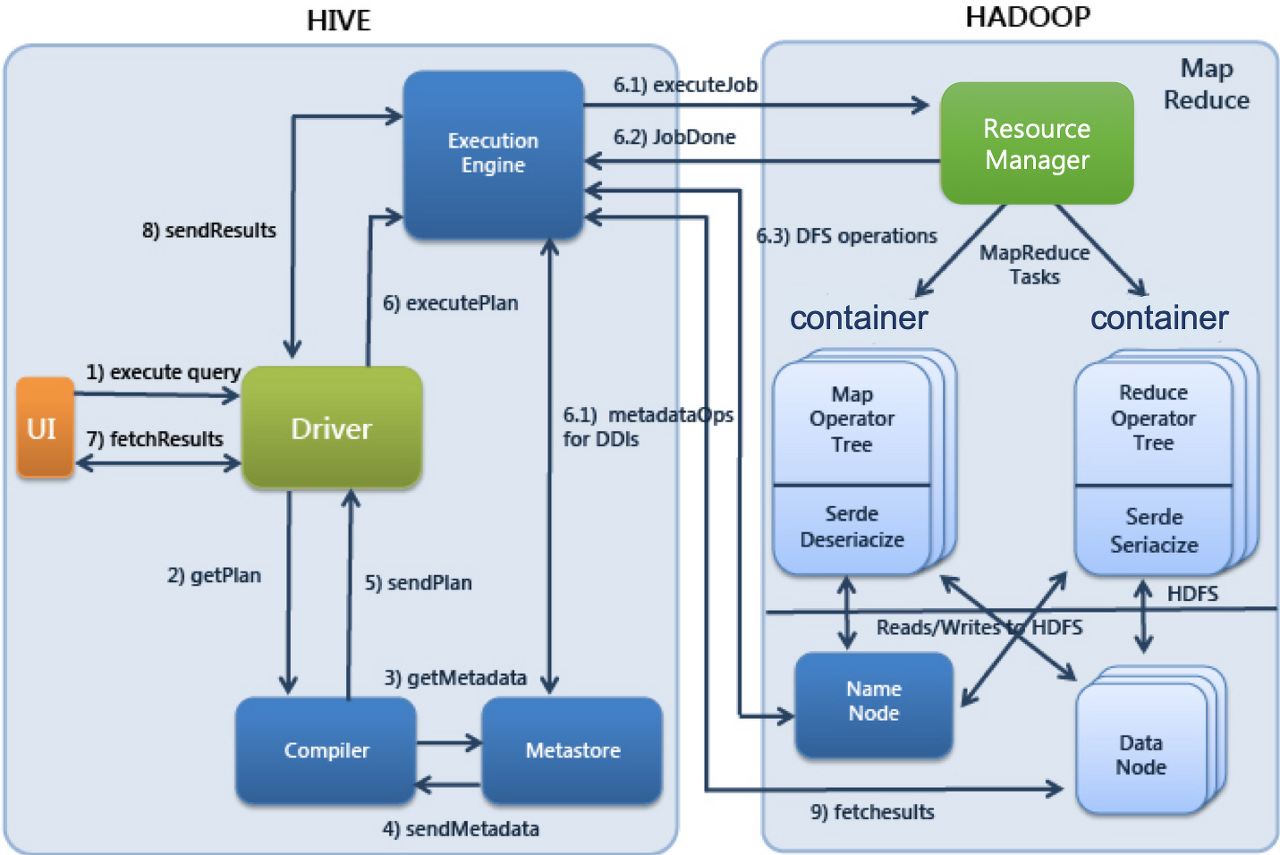
Hive 실행 순서
1) UI에서 사용자가 제출한 SQL문을 Driver가 Compiler에 요청하면 Metastore의 정보를 이용해 처리에 적합한 형태로 Compile 합니다.
2) Compile된 SQL을 실행엔진으로 실행합니다.
3) Resource Manager가 Cluster의 자원을 적절히 활용하여 실행시킵니다.
4) 실행 중 사용하는 원천데이터는 HDFS등의 저장장치를 이용합니다.
5) 실행결과를 사용자에게 반환합니다.